

Latest Econometric Features in EViews 12
EViews being the #1 best software for Econometric, leaves no feature behind in enhancing your analysis. EViews 12 has come up with many econometric advancements making your analysis more accurate and less time-taking.
Regression Variable Selection in Eviews
Selecting variables, among a large set of all variables, that are to be included in models is a very important step in analysis. EViews is best at automatically determining the variables to be used as regressors in a least squares regression. EViews includes three such techniques: Stepwise, and (new to EViews 12) Lasso and Auto-Search/GETS.
Each of these techniques are implemented in EViews as a pre-estimation step before performing a standard least squares regression. Before estimation, you must specify a dependent variable together with a list of always-included variable, and a list of selection variables, from which the selection algorithm will choose the most appropriate. Following the variable selection process, EViews reports the results of the final regression.
Indicator Saturation in Eviews
EViews 12 have added regression tools for testing outliers and structural breaks in a regression specification based on the indicator saturation approach.
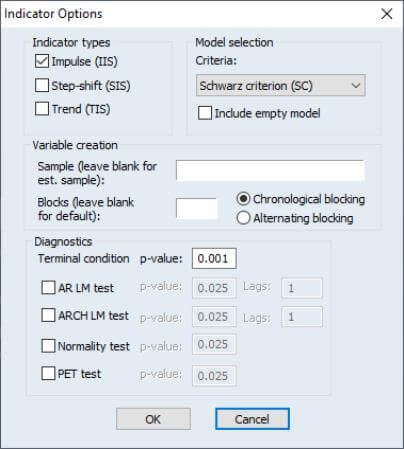
The indicator saturation approach is an extension of least squares regression for testing for outliers and structural breaks in a regression specification. The indicator saturation approach works by including indicator variables for outliers or structural breaks at every observation in the regression, and then employing the GETS algorithms to select which of the included variables should be retained in a final regression model.
To instruct EViews to detect indicators in your least squares regression, open the equation estimation dialog, enter your least squares specification in the Equation specification edit field, and select LS – Least Squares (NLS and ARMA) in the Method dialog. Next, click on the Options tab to display the dialog:
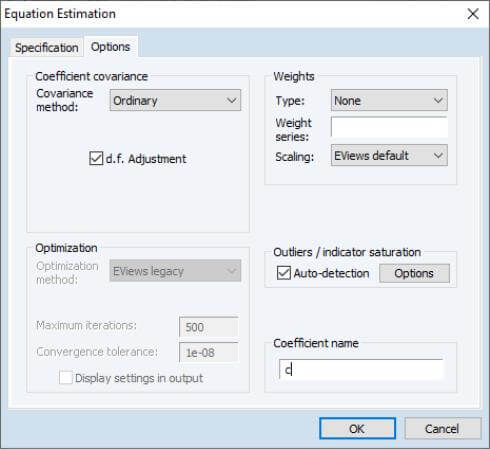
Select the Auto-detect check box in the Outlier/indicator saturation area on the right-hand side of the dialog, and then press the Options tab to bring up the Indicator Options dialog:
Mixed-Frequency Regression
Mixed Data Sampling (MIDAS) regression was introduced in EViews in earlier versions. MIDAS is an estimation technique which allows for data sampled at different frequencies to be used in the same regression.
More specifically, the MIDAS methodology addresses the situation where the dependent variable in the regression is sampled at a lower frequency than one or more of the regressors. The goal of the MIDAS approach is to incorporate the information in the higher frequency data into the lower frequency regression in a parsimonious, yet flexible fashion.
EViews 12 extends the existing MIDAS toolbox by adding additional estimation options. These new features allow you to use the General-to-Specific (GETS) method for variable selection and indicator saturation.
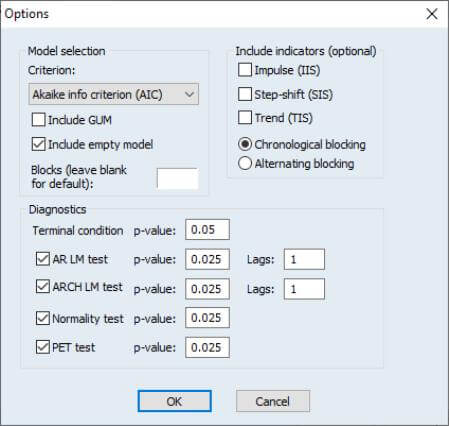
Elastic Net and Lasso
Elastic net regularization is a popular solution to the overfitting problem, where a model fits training data well but does not generalize easily to new test data. Depending on the particular parameters chosen for the elastic net model, some or all of the regressors are preserved, but their magnitudes are reduced.
EViews 11 includes tools for estimation of elastic net, ridge, and Lasso regression models. EViews supports estimation over a single lambda penalization parameter and a grid search over multiple penalization parameters. When multiple parameters are used, EViews also supports options for automatic generation of penalization parameters, as well as cross-validation tools for choosing the parameter with the lowest error.
EViews 12 offer a number of additions to the existing toolkit:
- new cross-validation options for selecting penalty function including rolling and expanding window methods for selecting training and test sets.
- new diagnostics showing training-test set cross-validation composition.
- estimation with observation and variable weights.
Impulse Response User Interface
EViews 12 features a new interface for computing and displaying impulse responses and confidence intervals for VAR and VEC estimators.
The prior impulse response interface coupled the choices for which impulses and responses to display and the method in which they were displayed, with the various options for computing the impulse response and standard error. Thus, if a user first displayed a multiple graph of impulse responses and then wanted to show the results in a table, or perhaps display a subset of those original responses, the procedure would have to be respecified and recomputed from the beginning.
The new, dynamic EViews 12 interface allows for interactive selection of the impulse and responses to be displayed, as well as the method of display. This flexibility is particularly important in light of the introduction of new, computationally intensive, VAR and VEC bootstrap confidence interval evaluation methods.

Bootstrap Impulse Response Confidence Intervals
EViews 12 introduces several new bootstrapping approaches to computing the confidence intervals for both VAR and VEC impulse responses.
These new tools allow you to compute residual bootstrap, residual double bootstrap, and fast residual double bootstrap estimates of these confidence intervals.
Panel and Pool Two-Way Cluster Robust Covariances
In many settings, observations may be grouped into different groups or “clusters” where errors are correlated for observations in the same cluster and uncorrelated for observations in different clusters. This cluster error correlation must be accounted for in computing estimates of the precision of regression estimates.
In a panel equation and pool settings, versions of EViews prior to EViews 12 offered tools for computing coefficient covariances accounting for clusters defined by cross-section units or by periods. Following the lead of the system estimation literature, these robust standard error calculations were termed “White cross-section” for clustering by period, to indicate that there was contemporaneous correlation between cross-section units, and termed “White period” for clustering by cross-section, to indicate that there was between period correlation within a cross-section unit.
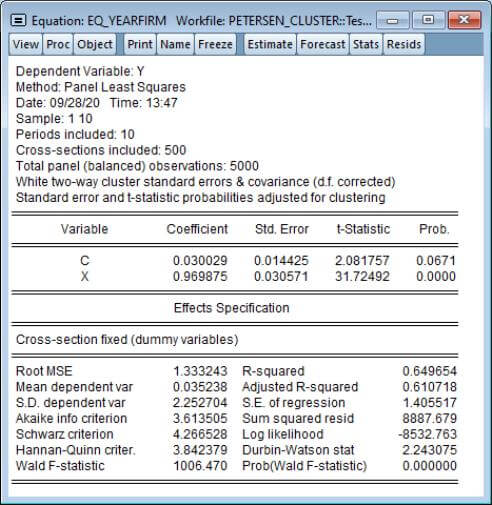
EViews 12 extends these tools to allow for computation of robust covariances when clusters are defined by both cross-section units and periods (Petersen 2009, Thompson 2011, Cameron, Gelbach, and Miller 2015).
To estimate a two-way cluster robust coefficient covariance in EViews, open the equation dialog in your panel workfile, then click on the Options tab to display the panel equations options page:
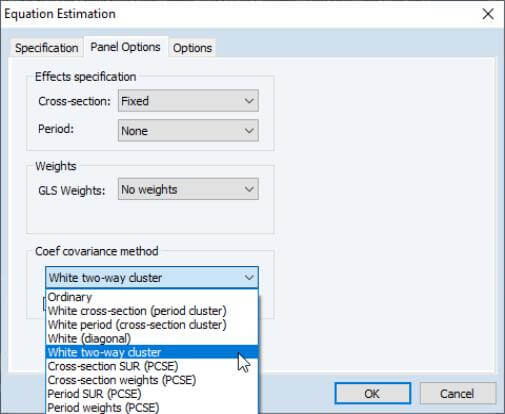
In the Coef covariance method combo on the left, select White cross-section (period cluster) for one-way period clustering, White period (cross-section clustering) for one-way cross-section clustering, White (diagonal) for unstructured heteroskedasticity robust covariances, or White two-way cluster for clustering by both cross-section and period.
Click on OK to estimate the equation with this option and display the estimation results.
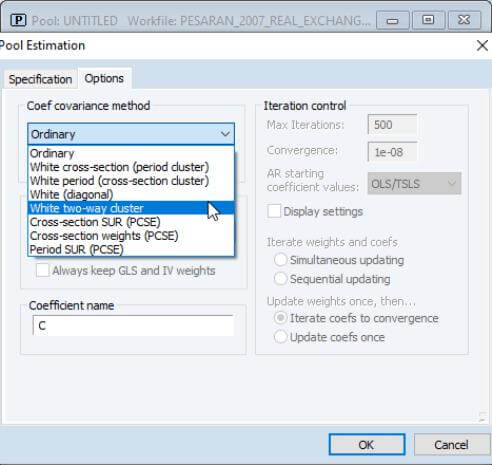
You may also compute two-way clustered standard errors in pooled data settings. Simply open the pool object, click on Estimate, and then on the Options tab:
Functional Coefficients Models
Functional coefficient regression is a semi-parametric approach to extend the standard regression framework by allowing the,
EViews 12 offers a completely revamped interface for estimating and working with these models along with new tools for examining the properties of your functional coefficients estimates:

- Enhanced Interface provides additional control over the computation of final and pilot bandwidths, with new methods for obtaining bandwidths.
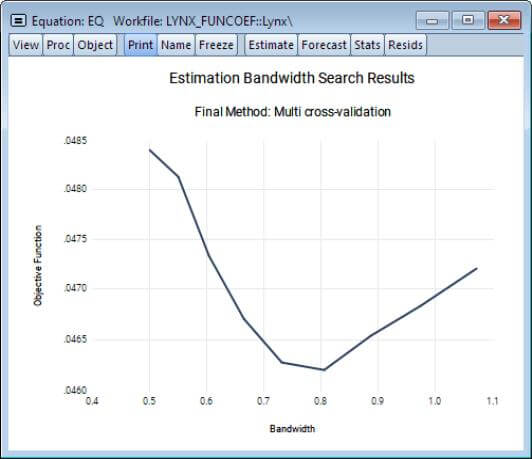
- New views permit examination of the bandwidth selection procedure results for both pilot and final bandwidths, and functional bias curves.
- Sophisticated forecasting engine performs static and dynamic forecasting via plug-in, Monte Carlo (asymptotic), Monte Carlo bootstrap, and full bootstrap methods. Stochastic resampling routines support computation of simulation based forecast standard errors and confidence intervals:
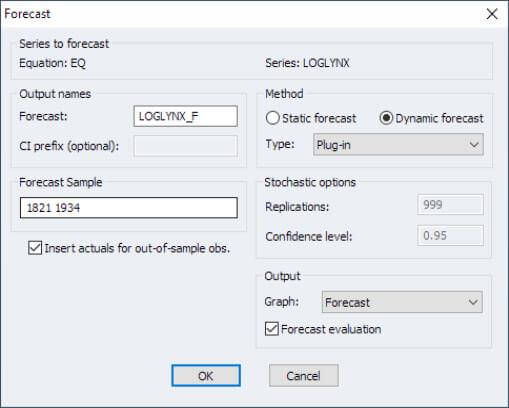
- New proc allows you to specify a local pilot bandwidth that is independent of the estimation pilot bandwidth for computation of diagnostic views.
Cross-Sectionally Dependent Panel Unit Root Tests
Since many economic time series have short samples but are observed over many cross-sections, multivariate unit root tests that combine results for different cross-sections, colloquially referred to as first generation panel unit root tests, offered improved statistical power over their univariate counterparts. These first generation panel unit root tests involve unit root testing on pooled panel data, with (possibly) individual trend, intercepts, and lag coefficients. While this framework is a natural first step, it comes at the steep cost of requiring cross-sectional independence.
Tests which account for cross-sectional dependence have been termed second generation panel unit root tests. EViews current supports two important second generation contributions: Panel Analysis of Nonstationarity in Idiosyncratic and Common Components (PANIC) due to Bai and Ng (2004), and Cross-sectionally Augmented IPS (CIPS), developed by Pesaran (2007).
Second generation panel unit root tests may be performed on a single series in a panel workfile or on a group of series in a workfile. To perform the test in the panel setting, you should open the series and then click on View/Unit Root Tests/Cross-Sectionally Dependent… EViews will display the dialog:

You may use the Type dropdown to choose PANIC or CIPS testing. Options include the lag selection for the ADF test, MQ testing, factor selection, and p-value simulation settings.
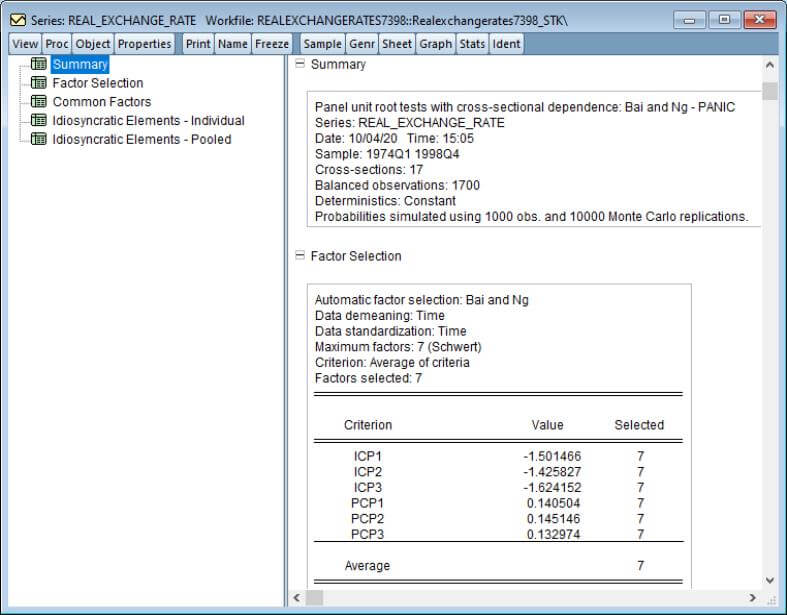
Note that in the group setting, you may perform the same test by opening the group object and clicking on View/Unit Root Tests/Cross-Sectionally Dependent….
Wavelet Decomposition – Eviews
Wavelet decomposition can decompose a series into its long-run behavior (smooths) and short run behavior (details). Among other things, wavelets may be used to
- compute the discrete wavelet transform to decompose a series into short and long run components at different scales
- obtain a long-run approximation to a series by neglecting transient features (thresholding)
- detect outliers
- decompose a series variance
EViews offers an easy to use interface for each of these tasks. For example, To perform wavelet decomposition in EViews 12, open the series of interest and select View/Wavelet Analysis/Transform…
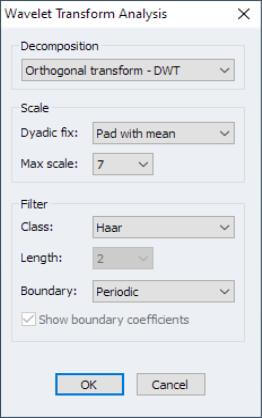
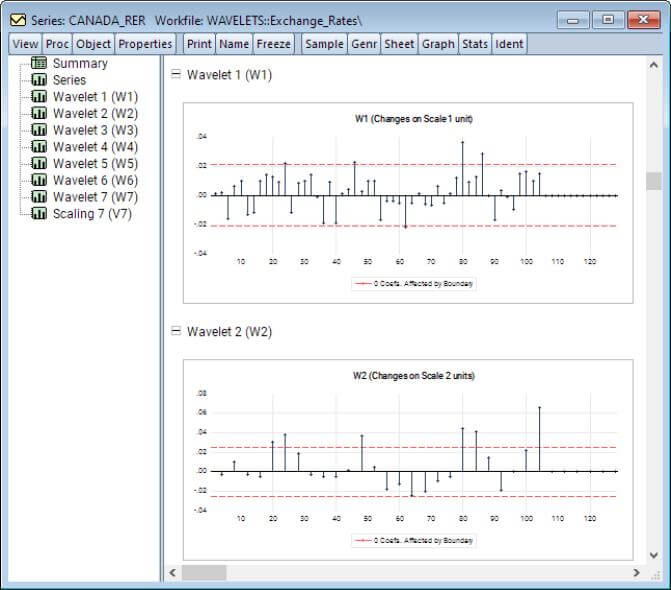
There are several entries under this menu item, each with its own set of options. The spool output lets you examine many features of the decomposition:
To detect outliers, select View/Wavelet Analysis/Outlier Detection…

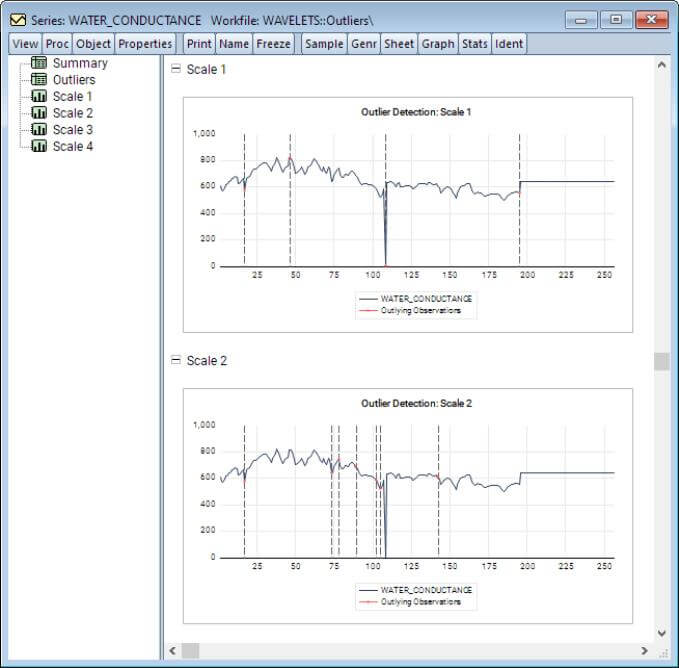
Number Of Factor Selection Methods
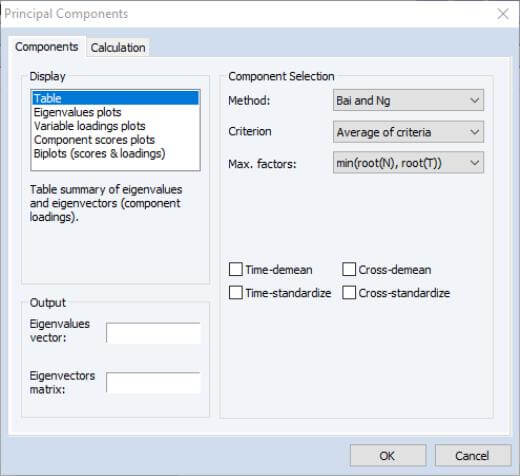
EViews 12 adds the Bain and Ng (200) and Ahn and Horenstein (2013) methods for determining the number of factors to retain to our existing principal components and factor analysis engines.
Source- http://www.eviews.com/help/helpintro.html#page/content%2Fwnew12-Econometrics_and_Statistics.html%23ww224818











 Copyright © 2020 | ® Numerical Analytics Instruments Pvt. Ltd | All Rights Reserved.
Copyright © 2020 | ® Numerical Analytics Instruments Pvt. Ltd | All Rights Reserved.